In meinem Vortrag zum Dreikönigsgespräch zur Digitalen Lehre an der Johannes Gutenberg Universität Mainz möchte ich auf einige Irrwege der Digitalisierung der Hochschullehre eingehen anhand von Beispielen verdeutlichen.
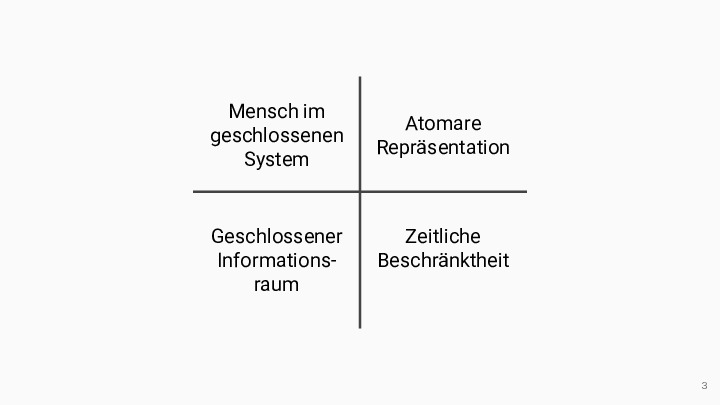
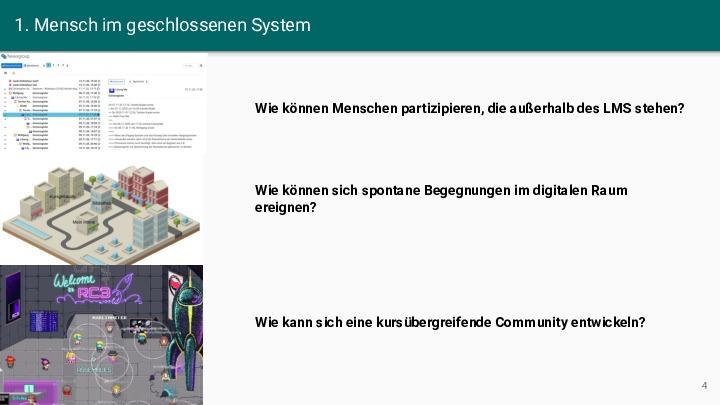
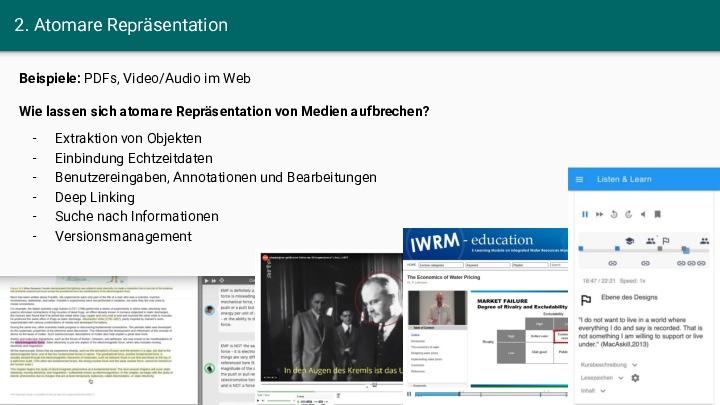
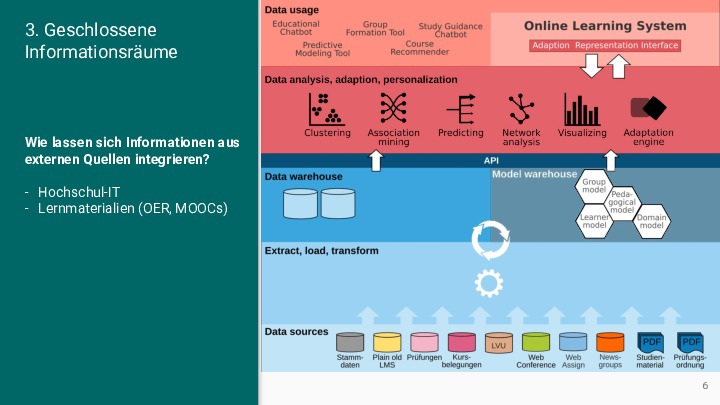
Abstract: Die Digitalisierung der Hochschullehre ist in mehrfacher Hinsicht durch starre technische Strukturen geprägt, die Lehr-Lern-Prozesse beeinträchtigen. Diese Starrheit reduziert einerseits die Komplexität der sozio-technischen Systeme und gewährt andererseits ein hohes Maß an Vorhersagbarkeit und Sicherheit. Das Zusammenspiel der Akteure mit den digitalen Artefakten erfolgt in definierten Bahnen, so dass sich nur selten emergente, d.h. neue, lebendige und sich selbst organisierende Strukturen in den digitalen Sphären herausbilden. Dieser Mangel an Emergenz ist auf geschlossene Systeme, atomare Repräsentationen von Artefakten und auf kurze zeitliche Horizonte zurückzuführen. Im Vortrag werden einige diese “failed pracitices” bzw. Anti-Pattern anhand von Beispielen und Gegenbeispielen vorgestellt.
Der Vortrag und die anschließende Diskussion am 6. Januar 2021 ist leider nur hochschulöffentlich, weshalb ich meine Folien an dieser Stelle als PDF und Bilddateien nachreiche: