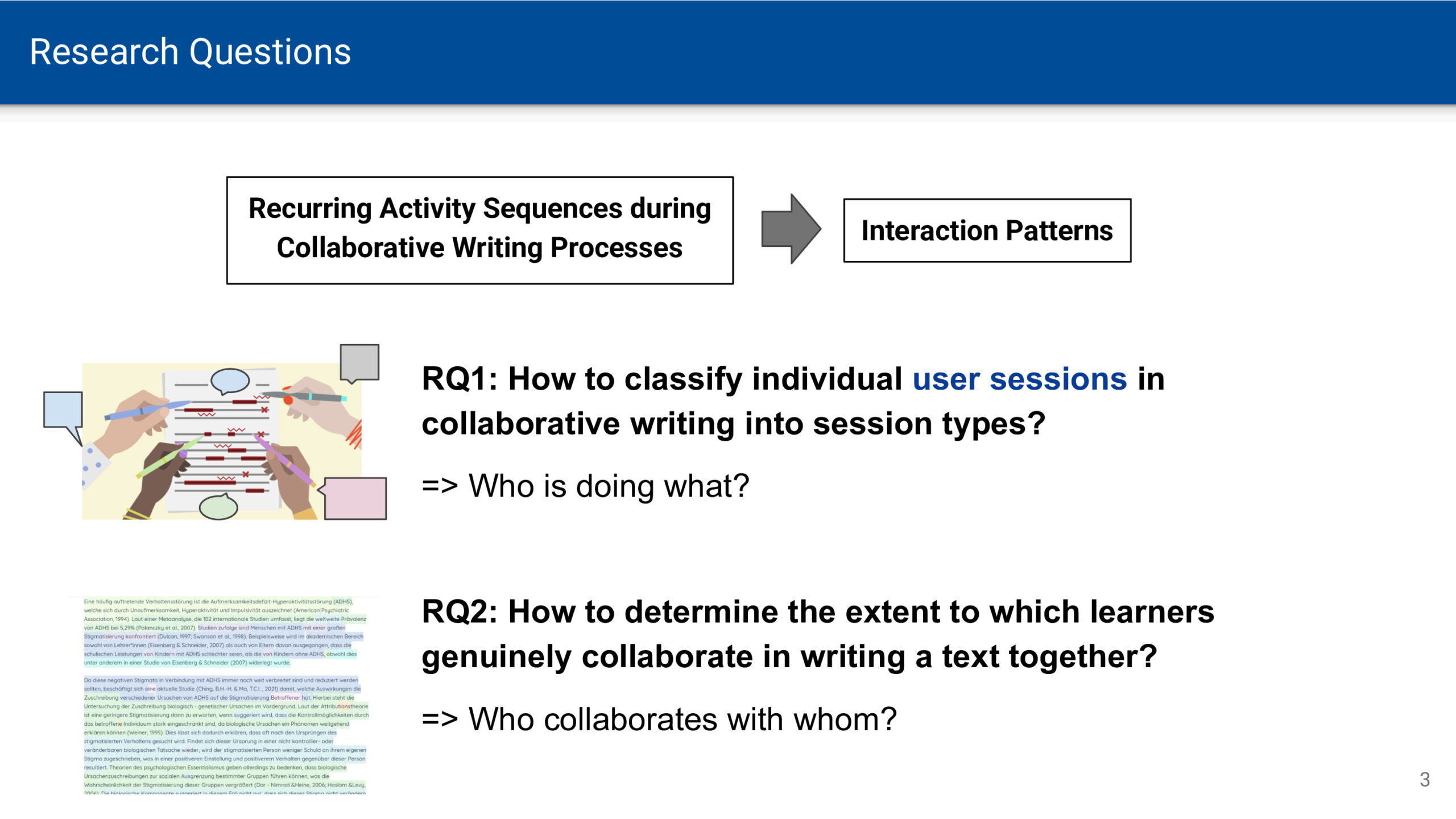
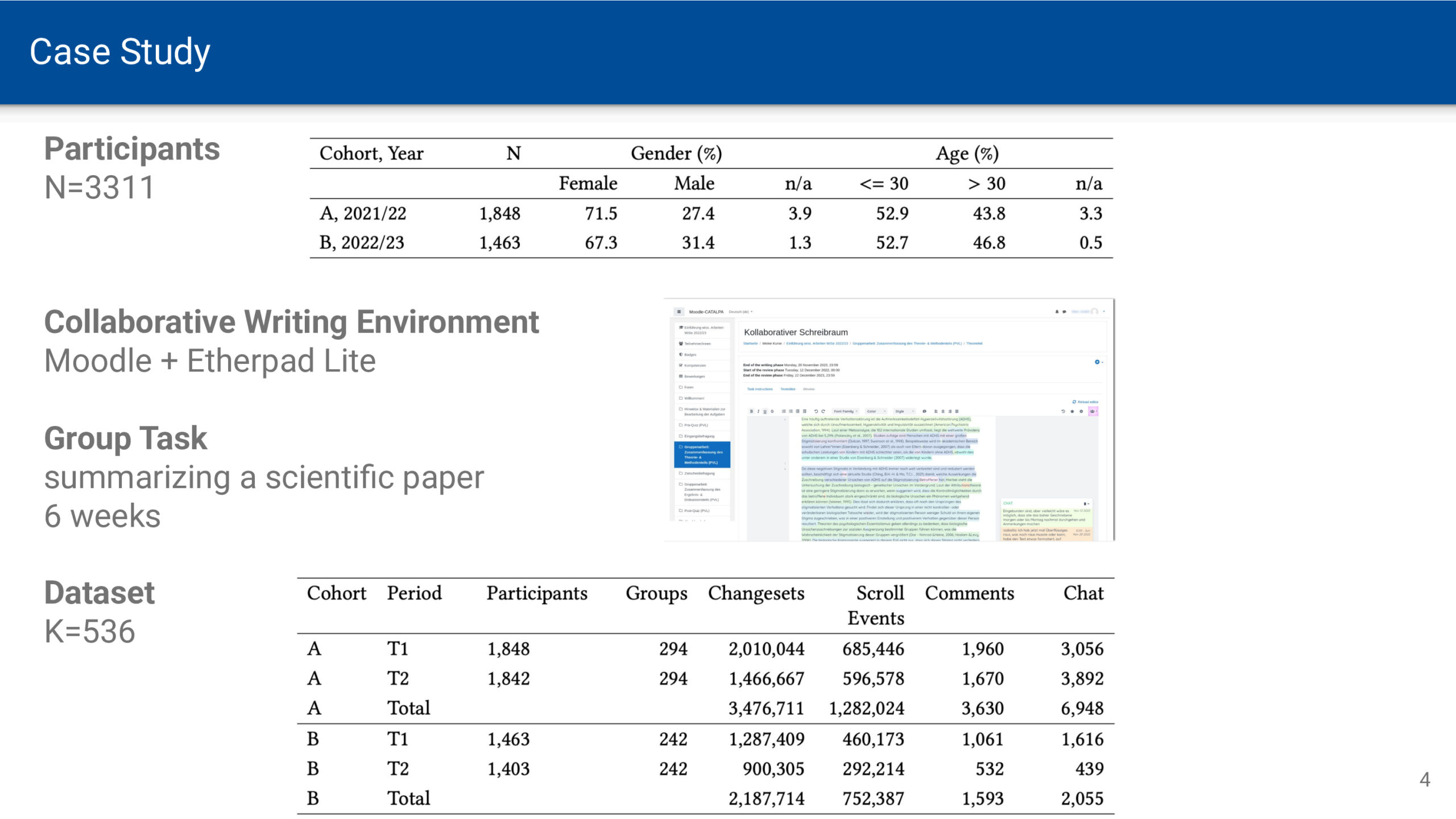
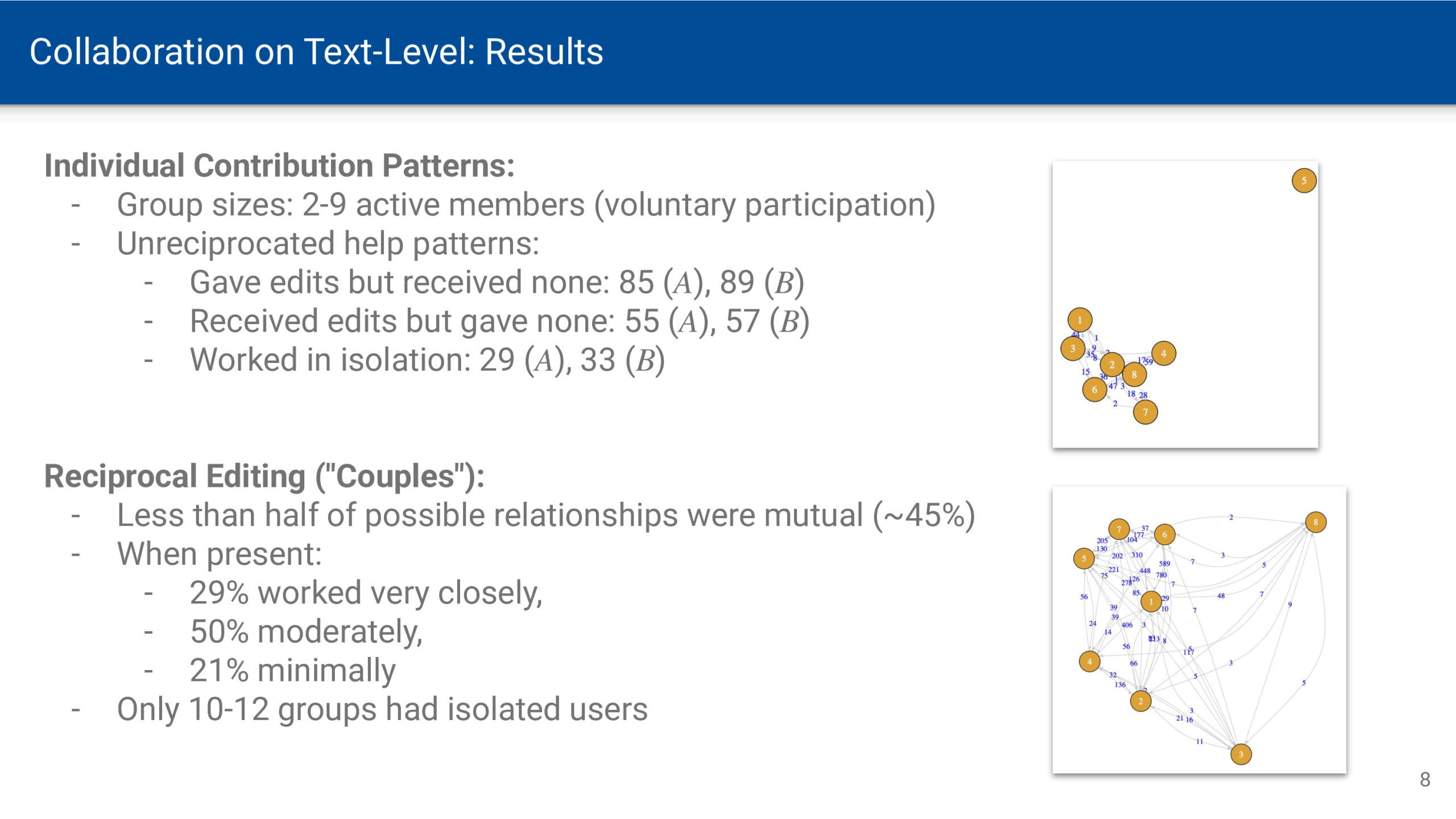
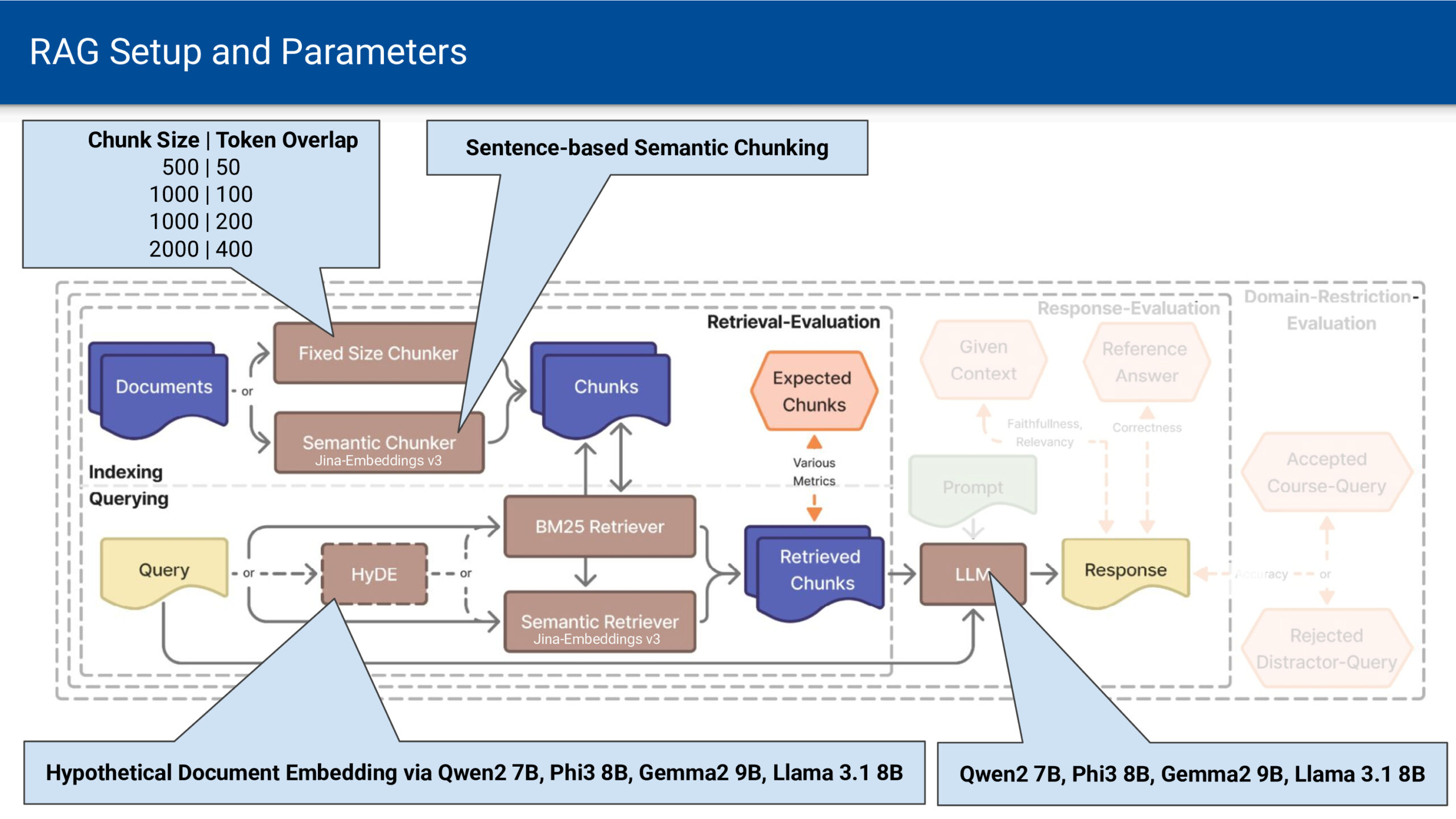
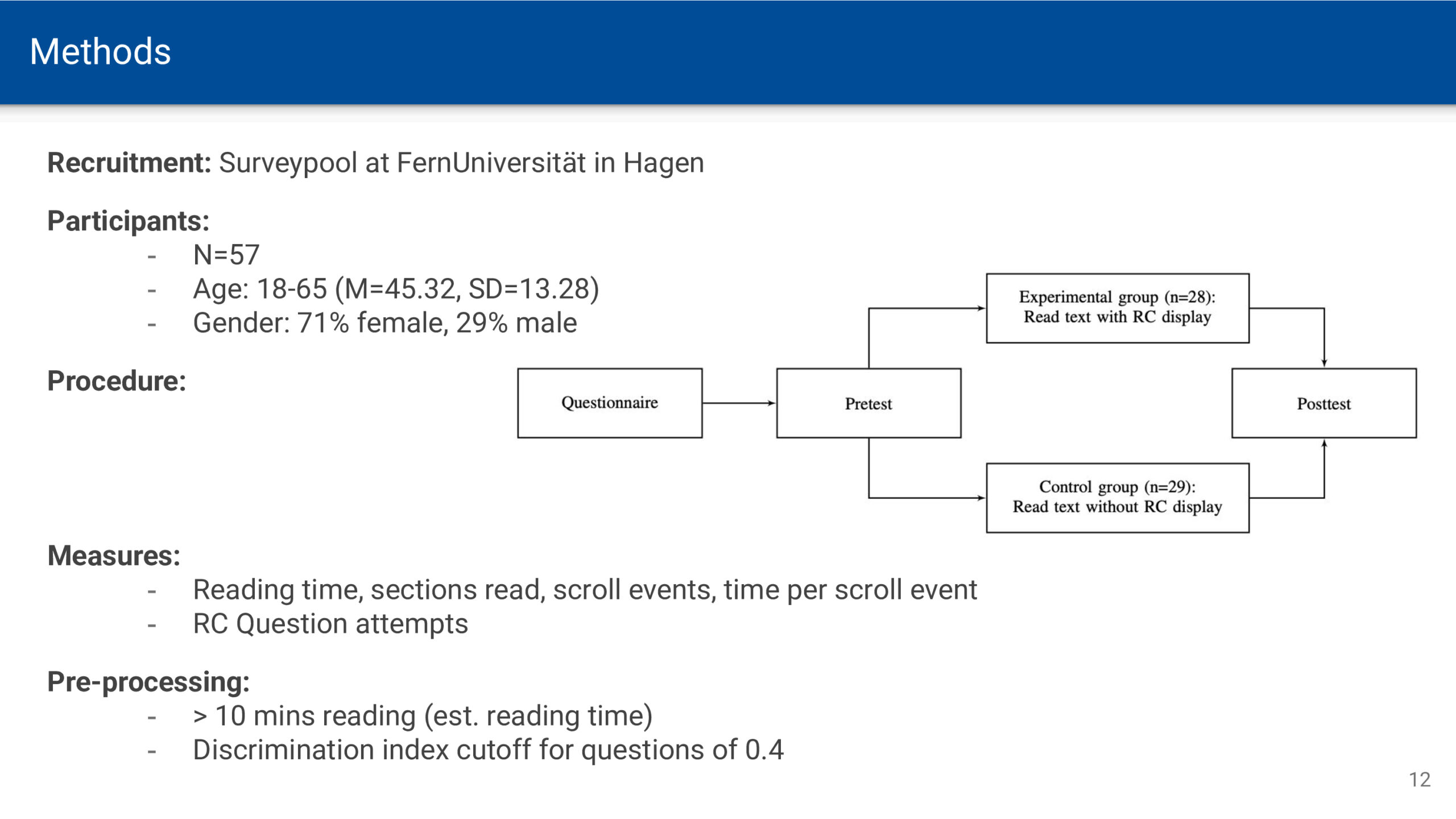
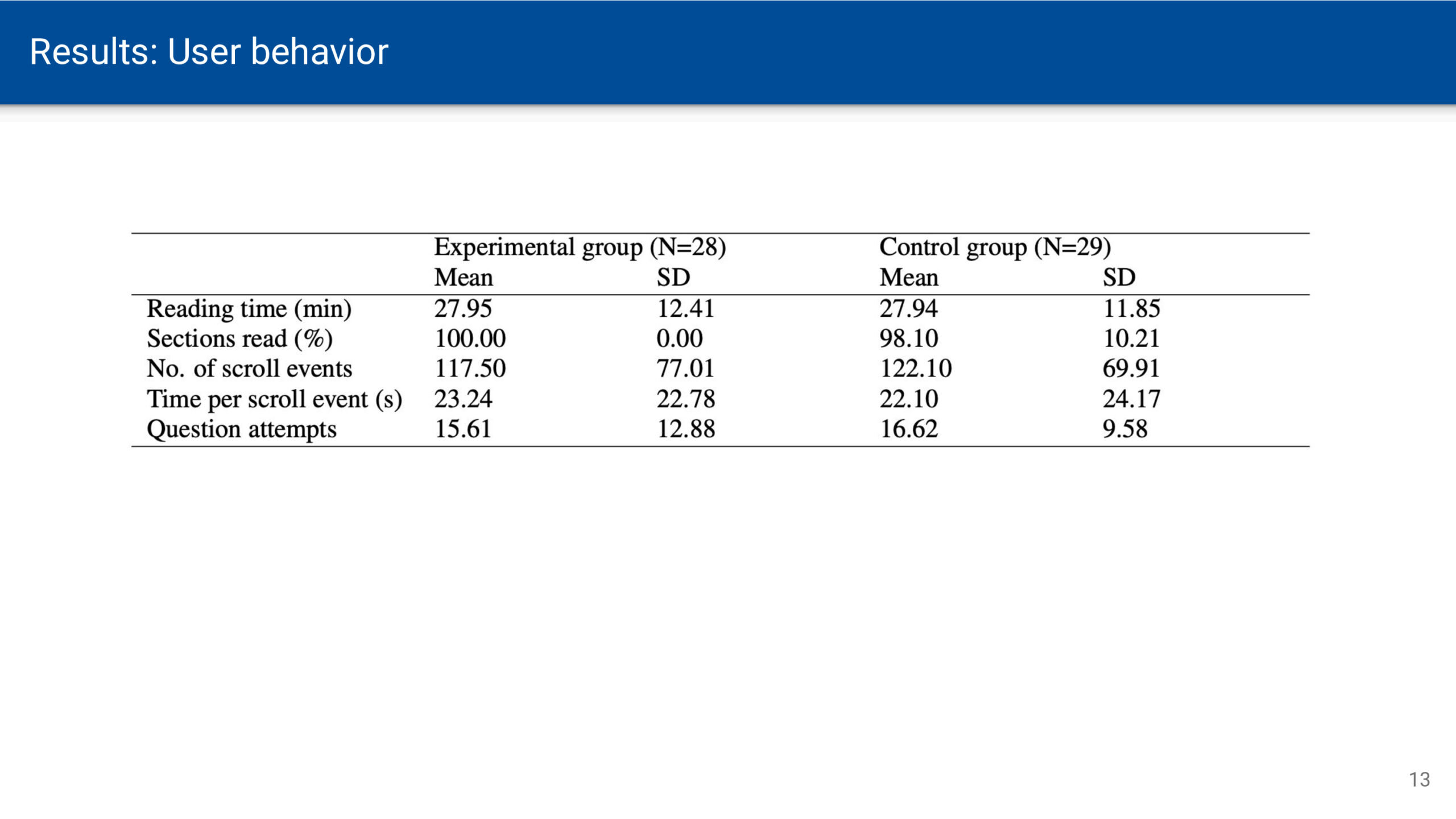
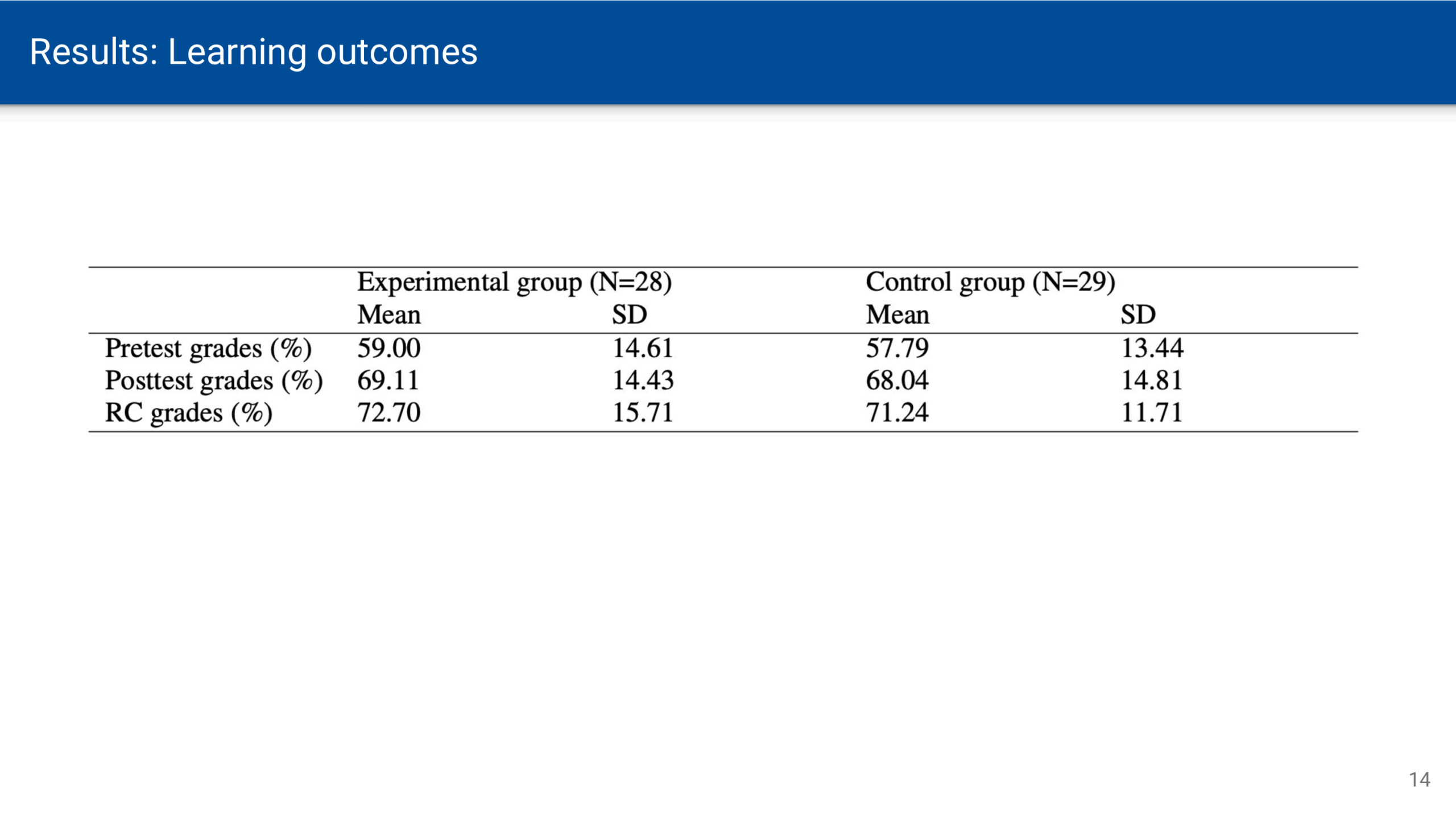
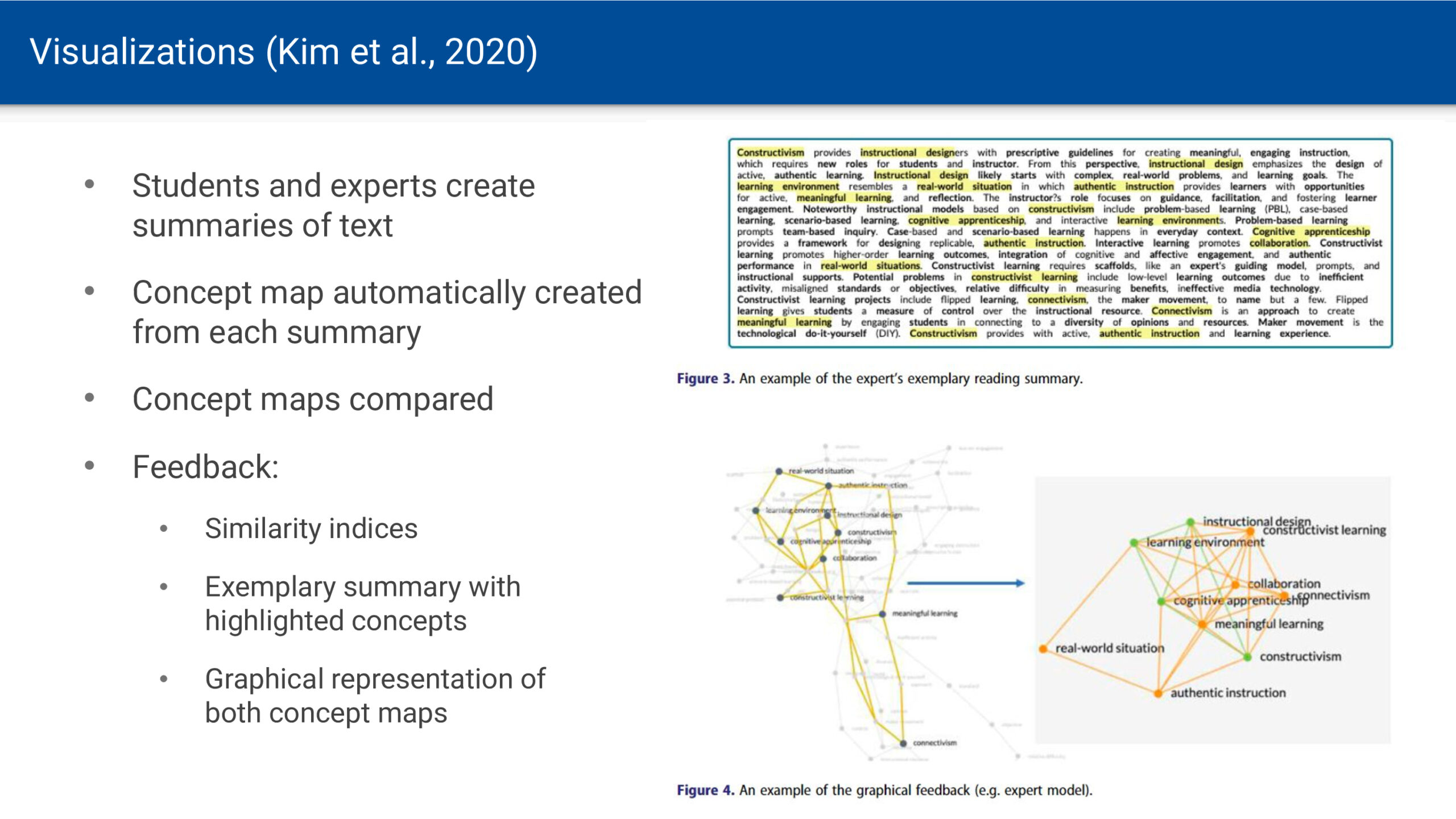
Wenn am Wochenende oder im Urlaub zeitliche Verpflichtungen durch Arbeit und Schule wegfallen, kann man sich zeitlich freier entfalten. Der Sonnenauf- und -untergang bleibt jedoch als Determinante von Hell und Dunkel bestehen. Zur Sonnenwende ist dieser Gegensatz umso deutlicher, je weiter man vom Äquator entfernt ist. Die Zeitmessung mittels Atomuhren bedingt eine gleichbleibende Dauer von Sekunden, Minuten und Stunden. Zeit vergeht dabei vollkommen gleichförmig und ohne äußere Einflüsse – eine notwendige Voraussetzung für astronomische Zeitmessung. Für Menschen, die sich an Tages- und Nachtrhythmen orientieren, ist diese Gleichförmigkeit jedoch eine künstliche Abstraktion, die der natürlichen Wahrnehmung von Zeit widerspricht.
Noch bevor sich astronomisch genaue Uhren durchsetzten, wendeten Mönche eine an die Sonnenbewegung angepasste Zeitmessung an. Ein Tag entsprach zwar 24 Stunden, doch wurden die 12 Tagesstunden (vom Sonnenaufgang bis zum Sonnenuntergang) und die 12 Nachtstunden (vom Sonnenuntergang bis zum Sonnenaufgang) jeweils in gleich lange Abschnitte geteilt. Da die Länge von Tag und Nacht je nach Jahreszeit variiert, waren diese Stunden unterschiedlich lang – man bezeichnet sie als Temporal-Stunde.
Im Winter sind die nächtlichen Temporalstunden länger als die Temporalstunden am Tage. Im Sommer ist es umgekehrt. Nur zur Tag-Nacht-Gleiche, d.h. am 21. März und 21. September, sind die Temporalstunden tags und nachts gleich lang und entsprechen der Dauer einer astronomischen Stunde.
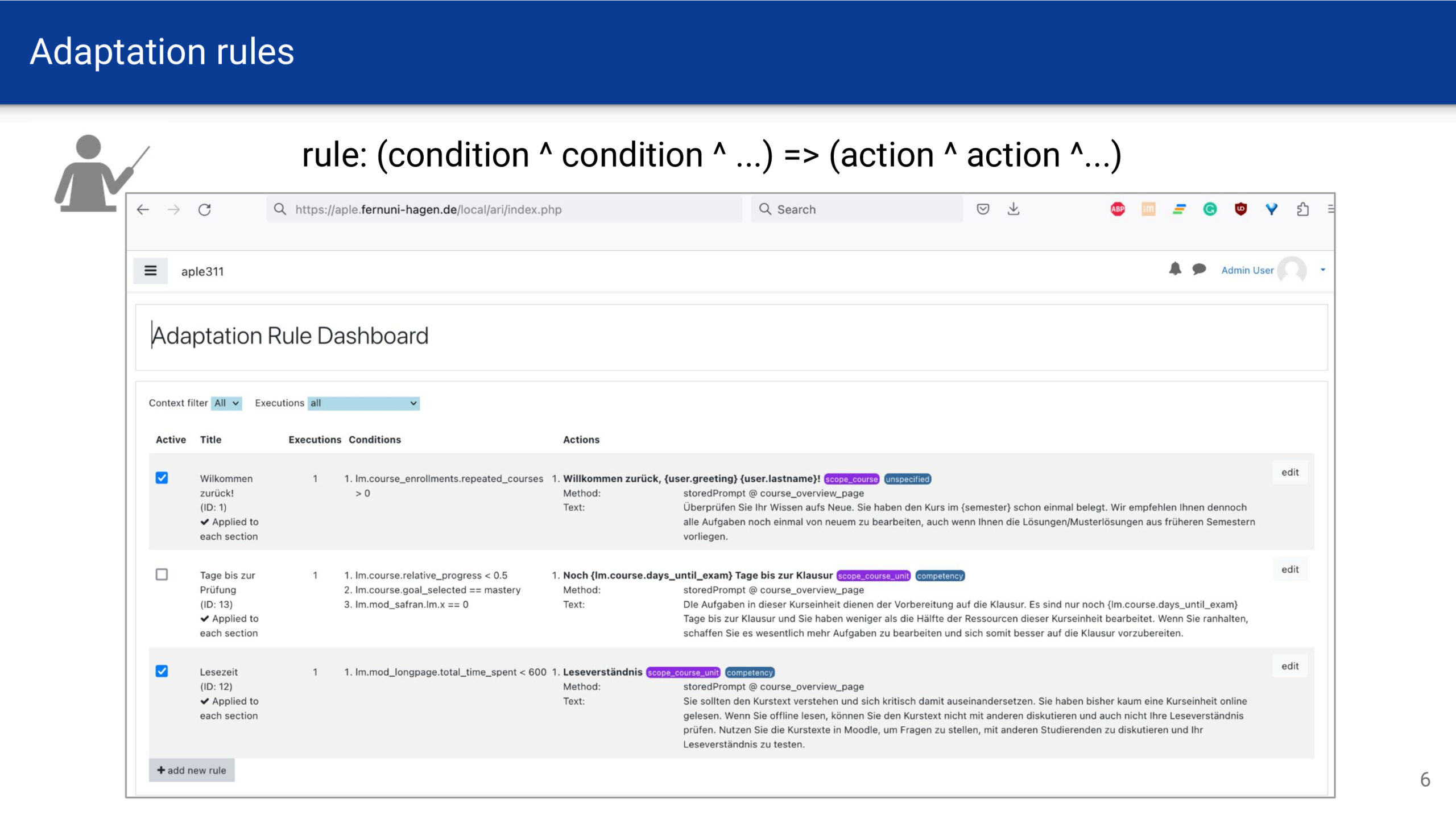
Temporalzeit bestimmen
Um sich eine solche Uhr besser vorstellen zu können, habe ich eine Anwendung programmiert. Für die Berechnung der Temporalzeit wird zunächst die geografische Position und in Folge die Zeiten für Sonnenauf- und Untergang bestimmt. Anschließend werden die Zeitintervalle zwischen dem Auf- und Untergang in 12 gleich große Abschnitte unterteilt. Die in Stunden und Minuten umgerechneten Intervalle werden im Dezimalformat und auf dem Ziffernblatt ausgegeben.
Die Anwendung ist als Webseite verfügbar und kann als WebApp auf dem Smartphone installiert werden: https://nise.github.io/temporal-time/
Wie lebt man nach der Temporalzeit?
Wie würde sich ein Leben nach der Temporaluhr auf unser Zeitempfinden und Wohlbefinden auswirken? Vermutlich würden typische Tagesaktivitäten subjektiv schneller vergehen. Ein achtstündiger Arbeitstag wäre im Winter tatsächlich kürzer und im Sommer länger als die mechanische Uhr anzeigt. Winterliche Tage ließen mehr Raum für Ruhe und Schlaf, während der Sommer noch ausgedehntere Tage und kürzere Nächte brächte – eine Betonung natürlicher Jahresrhythmen. Erstaunlicherweise fehlen zu dieser Frage wissenschaftliche Untersuchungen. Zwar erforscht die Chronobiologie die Auswirkungen verschiedener Schlafmuster und des durch Zeitumstellungen oder soziale Zwänge verursachten Jetlags, doch die gleichförmige Zeit als solche wurde noch nicht grundsätzlich infrage gestellt.